SWIFT¶
SHAP-Weighted Impact Feature Testing for Model-Aware Distribution Monitoring.
swift answers: which feature distributions have shifted in a way that actually
matters to my model? Traditional drift detection (KS test, PSI, …) flags any
statistical shift, regardless of whether the model cares. SWIFT compares
SHAP-transformed distributions between reference and monitoring data, weighting
every distribution change by its impact on model predictions — so only the shifts
that affect model behavior are flagged.
from swift import SWIFTMonitor
# Create monitor with a trained tree-ensemble model
monitor = SWIFTMonitor(model=lgb_model, n_permutations=200)
# Fit on reference data (stages 1-3)
monitor.fit(X_ref)
# Test monitoring data for drift (stages 4-5)
result = monitor.test(X_mon)
print(result.drifted_features)
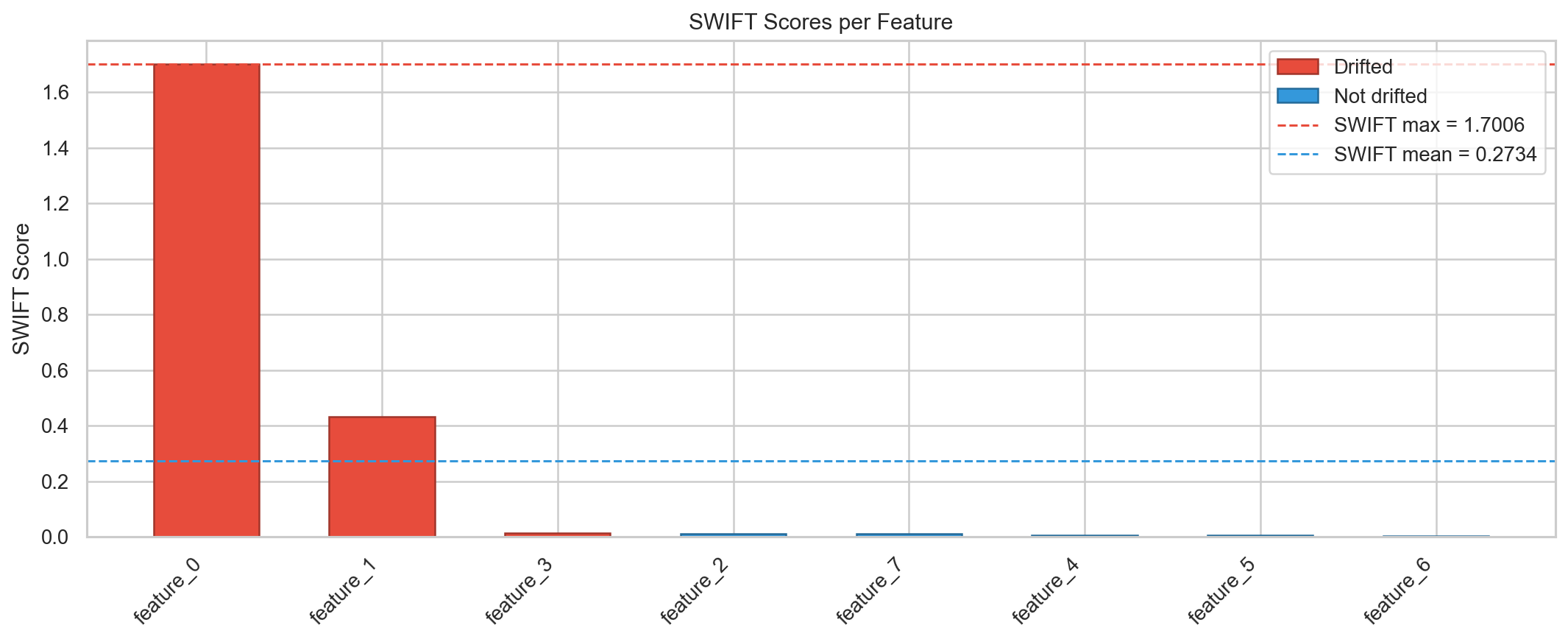
Highlights¶
- Model-aware by construction — feature values are mapped to the mean SHAP value of the model-derived bucket they fall in, so regions the model ignores cannot raise an alarm (how it works).
- Buckets come from the model itself — bucket boundaries are the split thresholds of the trained LightGBM or XGBoost ensemble, not arbitrary quantiles (decision points, buckets).
- Statistical rigor — Wasserstein distances on SHAP-transformed distributions, permutation-test p-values, and Benjamini-Hochberg or Bonferroni multiple testing correction (testing).
- scikit-learn compatible —
SWIFTMonitorinherits fromBaseEstimatorandTransformerMixin:fit/transform/score/test,get_params/set_params, andcloneall work (scikit-learn integration). - See the drift — per-feature bucket profiles (SHAP response curve +
observation density) and drift-colored score plots, all returning
(Figure, Axes)for customization (visualization). - Sample vs. sample mode — compare any two data windows against each other
with
X_compare, reusing the SHAP transformation learned from the reference (FAQ).
Where to start¶
- Getting started — install and your first drift test in five minutes.
- How it works — the full five-stage pipeline, from split thresholds to corrected p-values.
- Quickstart tutorial — a runnable notebook, from training a model to reading the drift verdict.
- API reference — every public class and function.
Citation¶
@article{swift2025,
title={SWIFT: SHAP-Weighted Impact Feature Testing for Model-Aware Distribution Monitoring},
year={2025}
}